Unraveling the Web of Confusion: Ofcom's 'One Touch Switch' Regulation
Have you read through all of OFCOM’s ‘One Touch Switch’ documentation? No? You’re not alone. It’s contradictory, heavily redacted and incomplete; in addition to being extremely dense and technical. The apparent goal of the regulation is to ensure switching internet service providers is a seamless process for consumers. However, its implementation has raised several concerns and created far more confusion than clarity… and we’re only just getting started. In this article we will delve into a few of the issues and concerns we have raised around Ofcom’s ‘One Touch Switch’ regulation.
Complexity of Switching Mechanism:
One of the primary issues with the ‘One Touch Switch’ regulation is its complexity. The goal was to simplify the process of switching service providers, but the plethora of technicalities and administrative requirements might have backfired. Consumers may find it daunting to navigate through the intricate switching mechanism, leading to hesitation and confusion. As OTS will become the primary route for new customers, ensuring that it is fully integrated into your existing OSS/BSS and creating an organic and seamless process for customers is essential for success in a competitive market.
Disparities Among Service Providers:
While Ofcom intended to level the playing field, ‘One Touch Switch’ seems to have created disparities among service providers. The ‘Big Six’ have collaborated together to create TOTSCo and the associated TOTSCo Hub. As the vast majority of customers sit with these providers, smaller Alt-Nets have little option but to use it. Many of them lack the same level of resources of their larger counterparts, and may struggle to meet the stringent requirements, leading to an uneven competitive landscape.
Abusing the System
The promise of a seamless switching process is enforced by tight SLAs. Ofcom requires losing providers to respond to a match request and provide a conditions letter within 60 seconds. However, if a customer’s preferred method of communication is via ‘post’, this 60 second SLA becomes 24 hours for the conditions letter. It’s not a big leap to imagine organisations abusing this fact and ensuring ‘post’ is the primary method of communication for their customers, therefore delaying the switch and allowing more time for retention processes to kick in.
Data Privacy and Security Concerns:
With the ‘One Touch Switch’ regulation, consumers are required to provide sensitive personal information to facilitate the switch. This raises concerns about data privacy and security, especially when leveraging hosted solutions outside of your own business. Solution providers might have access to more personal data than necessary, potentially leading to misuse or unauthorised access.
Customer Lock-in and Early Termination Fees:
The contradiction arises when the ‘One Touch Switch’ regulation attempts to offer consumers more freedom while they remain bound by lock-in periods and early termination fees. Providers might resort to increasing these fees to discourage customers from switching, limiting the effectiveness of the regulation and trapping consumers in unfavorable contracts.
Lack of Clear Communication:
The introduction of ‘One Touch Switch’ has seen service providers scrambling to comply with the new rules. The documentation released by Ofcom has changed significantly over the past 12 months and continues to be a moving target. This lack of clear communication and ambiguous terms and conditions have led to misunderstandings, leaving organisations with an unclear picture of the implications.
Losing Providers with Poor Implementation
One foreseeable issue with ‘One Touch Switch’ may arise when a losing provider has poor or inaccessible customer data, e.g. UPRN is not matched to an address. Losing providers may still adhere to the 60 second response time, but continue to reject switch matching indefinitely because they cannot find the customer based on the four required data points. Additionally, losing providers who are leveraging an ineffective hosted solution are subject to potential downtime or delays in responses that are outside of their control.
Lack of Contingency Planning:
The regulation appears to lack a comprehensive contingency plan for potential issues or disputes that may arise during the switching process. A full reliance on the TOTSCo Hub creates a single point of failure and the absence of clear guidelines for consumers and service providers may cause difficulties in resolving conflicts.
Consumer Education:
The long term success of ‘One Touch Switch’ hinges on consumer awareness and understanding. However, there is a lack of sufficient efforts by Ofcom to educate consumers about the regulation and its implications, potentially leaving them vulnerable to exploitation. With a firm go-live date now in place and OTS set to be the primary route to new business for organisations, this needs to be addressed sooner rather than later.
Ofcom’s ‘One Touch Switch’ regulation offers the promise of greater consumer choice and competitive services. However, its implementation has brought forth a myriad of issues, unknowns, and contradictions. ThirdEye Consulting have built an ‘Out of the Box’ One Touch Switch solution to take the pain away from service providers. This fully managed solution will adapt to any new changes to the regulation and fosters an environment where consumers truly have the power to switch seamlessly and make informed decisions about their services.
Come and meet the ThirdEye team at Connected Britain on September 20th & 21st to hear more about our OTS solution.
Read More
ThirdEye Ai Acceptable Use Policy
Today we’re introducing our new ThirdEye Ai Acceptable Use Policy – a guide for our staff to ensure secure AI tool usage.
We’re excited to be at the bleeding edge of AI innovation whilst prioritising security to best support our customers’ AI implementations.
Curious to delve into the details? Read the full policy below.
- Overview
Artificial Intelligence (AI) tools are transforming the way we work, and we both want to be on the edge of this wave of innovation. AI has the potential to automate tasks, improve decision-making, and provide valuable insights into our operations; however, the use of AI tools also presents new challenges in terms of information security and data protection. This policy is a guide for employees on how to be safe and secure when using AI tools, especially when it involves the sharing of potentially sensitive company and customer information.
- Purpose
The purpose of this policy is to ensure that all employees use AI tools in a secure, responsible and confidential manner. The policy outlines the requirements that employees must follow when using AI tools, including the evaluation of security risks and the protection of confidential data.
- Policy Statement
Our organization recognizes that the use of AI tools can pose risks to our operations and customers. Therefore, we are committed to protecting the confidentiality, integrity, and availability of all company and customer data. This policy requires all employees to use AI tools in a manner consistent with our security best practices.
3.1 Security Best Practices
All employees are expected to adhere to the following security best practices when using AI tools:
3.1.1 Evaluation of AI Tools
Employees must evaluate the security of any AI tool before using it. This includes reviewing the tool’s security features, terms of service, and privacy policy. Employees must also check the reputation of the tool developer and any third-party services used by the tool.
If you have a tool that you think is of value to ThirdEye and you have conducted your own review, please post the tool to the AI Tooling slack channel. AI Tools should be approved into one of two categories below
3.1.2 AI Tool Classifications
Public Use: AI Tools that are publicly available and submissions of questions are contributing to the public learning base. For these tools, no confidential internal information, Personally Identifiable Information, security information or credentials, client data or client information (including client name) should be submitted for any AI prompt. If you have questions about what is okay to use in the prompt, please speak to members of the AI Vanguard Group for guidance.
Do not use the result of any AI tool without careful review, as we need to ensure that toxicity and other potentially harmful content is not making it into any used materials. Use these guidelines for any unapproved AI tools even if they claim to offer secure use.
Secure Use: AI Tools that have security features built in to scrub sensitive information and filter toxicity. These will be paid tools that ensure privacy whilst still leveraging the AI engines of companies like OpenAI. Examples of this are Salesforce GPT toolings.
When writing prompts for these tools, you can use PII and sensitive company information – however we still ask for discretion and consideration before doing so. While there are security features built in, please do not enter anything that you would not say out loud in the middle of the office.
- Interacting with AI
While as of now we do not believe that AI has become sentient, we do not know when it may and would assume that it will use the history of human interactions to form their view of humanity. For this reason, ALWAYS treat AI bots courteously and with respect. Thank the bots for particularly good results, and generally be as kind to the bots as you would any other well liked and high-performing co-worker. If you think this is unnecessary, ThirdEye will pay for a copy ‘The Complete Robot’ by Isaac Asimov or organise a screening of ‘The Terminator’.
- Review and Revision
This policy will be reviewed and updated on a regular basis to ensure that it remains current and effective. Any revisions to the policy will be communicated to all employees.
Conclusion:
Our organization is committed to ensuring that the use of AI tools is safe and secure for all employees and customers, as well as the organization itself. We believe that by following the guidelines outlined in this policy, we can maximize the benefits of AI tools while minimizing the potential risks associated with their use.
- Revision History
| Date of Change |
Responsible |
Summary of Change |
| June 2023 |
Jeff Steinke |
Establishment of Policy |
Read More
ThirdEye Salesforce Summit Status
What is Summit Status?
Summit Status is the highest level of partnership that a Salesforce Partner can achieve. This elite status is reserved for partners who have demonstrated deep expertise in Salesforce solutions and have a proven track record of delivering exceptional customer experiences, commitments to learning & development along with social impact causes. Summit Partners have access to a range of exclusive benefits, including early access to new features and products, increased collaboration with Salesforce teams, and the ability to participate in unique events and programs.
How Did We Get Here?
At ThirdEye, providing our clients with exceptional service and innovative solutions is part of our DNA. Our team of certified Salesforce consultants has worked tirelessly to help our clients achieve their business goals and drive growth through Salesforce solutions.
Our journey to Summit Partner began with our deep understanding of Salesforce capabilities, and the ability to deliver exceptional service to our customers whilst being involved in amazing social impact projects such as Pledge 1%
We have completed numerous successful Salesforce implementations and have received positive feedback from our clients, which has helped us achieve this elite status.
What Does This Mean for Our Clients?
As a Summit Partner, we have early access to the latest Salesforce innovations and with top tier talent, we can help our clients stay ahead of the curve and deliver personalised projects no matter the challenge. We are focused to helping our clients succeed, and our Summit Status is a reflection of our commitment to delivering excellence.
Get in Touch
If you are interested in learning more about our Salesforce solutions or how we can help your business reach its full potential, please contact us today.
Read More
Delivery Task and Project Management
Project and Task Management
The basics
We approached the solution in the following way: the first things we need are a custom object Project__c and a custom object Delivery_Task__c with a lookup to Project__c,. This provides our basic architecture on the front end.
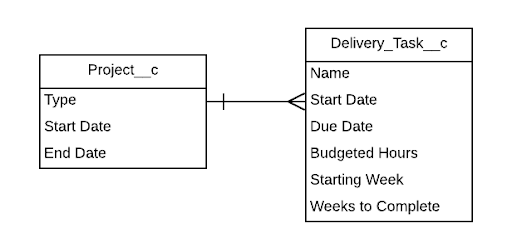
Next we need to store the information about the tasks we are going to create. For this we will use custom metadata types. Our custom metadata object will hold information about the type of project the task should be created for, how many hours should be assigned to this task, as well as where in the project lifecycle the task falls.

The Automation
Creating the Delivery Tasks
Our first piece of automation will be triggered on creation of the project record itself. A flow will get our metadata records and use them to create the delivery tasks.
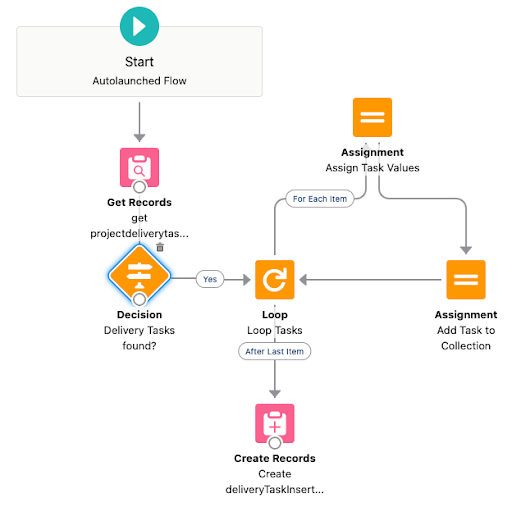
- 1. Get projectDeliveryTaskMDT: Get a collection of all the metadata records Project_Delivery_Task__mdt where Type__c = Project__r.Type__c.
- 2. Delivery Tasks found?: If no tasks are found in step 1 we will exit the flow.
- 3. Loop Tasks: We will loop all the tasks we found in step 1.
- 4. Assign Task Values: We will assign all values from the Project_Delivery_Task__mdt record to a sobject variable representing the Delivery Task

- 5. Add Task to Collection: The sobject variable will be added to to an sobject variable collection.

- 6. Create deliveryTaskInsertList: This will create all the Delivery_Task__c records.
Setting the Start Date
Great, our project now has all of its delivery tasks. The next part of the process is to determine when these tasks are scheduled to be carried out.
Our second flow will be triggered when the field Start_Date__c is populated on the Project record. We have a validation in place to ensure that all projects start on a Monday.

- 1. getdeliveryTasks: We will get all the delivery tasks related to the project.
- 2. For each delivery task, we will calculate and assign:
- Start Date: ({!thisProject.Start_Date__c}+(({!Loop_deliveryTasks.Starting_Week__c}-1)*7)) If the value of Starting Week on the task = 1, the Start Date will be the same as that of the Project. If Starting Week = 2, it will start the Monday after the Project Start Date.
- Due Date: {!Loop_deliveryTasks.Start_Date__c}+(({!Loop_deliveryTasks.Weeks_to_Complete__c}*7)-3) If the value of Weeks to Complete = 1, the Due Date of the Delivery Task will be the Friday of the same week in which the task Start Date is. If the value of Weeks to Complete = 2, the Due Date of the Delivery Task will be the Friday of the week after the Task Start Date.
- 3. Add to Group: The task is added to an insert sobject collection variable.
- 4. tasksToUpdate: checks to see whether there are any tasks to update.
- 5. Update Tasks: All the tasks in the sobject collection variable are updated.
- 6. getLastTask: The task with the greatest (furthest out) Due Date is found.
- 7. Assign Project End Date: This date is assigned as the End Date of the Project.
- 8. Update Project: The Project record is updated.
Considerations and Enhancements
- Further sub categorisation of projects/tasks: A Subtype field can be added to increase the flexibility of the Task Creation process.
Read More
Salesforce, ITSM & ITIL
What are ITSM and ITIL?
- ITSM: Information Technology Service Management
ITSM refers to the creation, managing and delivery of IT Services to customers; it covers the processes as well as the technology to realise maximum efficiency and value.
- ITIL: Information Technology Infrastructure Library
ITIL is a framework that defines the best practices around implementing ITSM successfully.

Many other frameworks exist and can be used as the basis for ITSM, such as COBIT 5, eTOM, ISO/IEC 20000, MOF (Microsoft Operations Framework) etc, however, ITIL is the most widely adopted. There’s a lot more to ITSM & ITIL; the above is intentionally a super-simplified explanation; many articles on ITSM and ITIL are already available online that cover both in great depth.
The element of ITIL that Salesforce has now added to their offering is the different work types and how they relate, which are as follows:
Service Request:
A request from a User for information or advice or a standard change. For example, reset a password or provide standard IT services for a new user. A service desk usually handles service requests.
In ITIL a standard change is a change that doesn’t require authorisation, such as a password reset or change of email address for a user, as opposed to a normal change or emergency change where authorisation is required.
Incident:
Any event which is not part of the standard operation of a service and which causes, or may cause, an interruption to, or a reduction in, the quality of that service.
Problem:
The unknown underlying cause of one or more Incidents. These might be resolved in the short term by implementing a workaround.
Change:
The addition, modification, or removal of approved, supported or baselined hardware, network, software, application, environment, system, desktop build, or associated documentation.
To understand the above work types, let’s use the example of an internet service provider. A customer may be experiencing a loss of connectivity, which they report as an Incident, several users/customers may report similar incidents and if a significant amount of customers are affected this would be classified as a major Incident. A problem would then be created to perform root cause analysis to identify the cause, for example, a hardware fault. One or more change requests would then be created to request approval for the faulty hardware to be replaced and once the change requests have been approved and the change implemented, the problem will have been resolved and the Incidents related to that problem would also have been resolved.
To implement the above model previously, it was necessary to either A) Create separate record types for each work type and enforce the hierarchy between them, or B) Create custom objects and relationships.
With the winter 22 release, Salesforce Service Cloud now contains standard objects to allow customers to implement an ITIL compliant solution. To enable these objects and make them available for use, search for ‘Incident Management’ in the setup menu and then enable the feature using the toggle switch. The Incident Management feature is included as part of the standard Service Cloud licence and is available at no extra cost.

What does the incident management feature include?
The incident management feature includes the following objects:
Case-related issue, incident, problem-incident relationship, problem, change request related issue & change request. The ERD below shows how these objects relate to each other to help facilitate an ITIL-compliant solution:

In this model, the standard case object is used for Service Requests. Each ITIL specific work type has its own standard object; standard junction objects are then used to create the relationships between the different work types. This removes the need to use multiple record types on the case object or create custom objects to achieve an ITIL compliant solution.
Although Salesforce now provides us with the objects, we still need to create supporting automation to implement a comprehensive end-to-end solution that conforms to the ITIL framework and a customer’s specific requirements. However, this is a massive step towards standardising the process and facilitating a universal approach to ITIL compliance across Salesforce Service Cloud orgs, and we are very excited to see what comes down the road in future releases!
If you’re an existing or potential Salesforce Service Cloud customer looking to implement or upgrade to an ITSM solution based on the ITIL framework and supported by the power of the Force.com platform, ThirdEye has the experience and the expertise to help you realise your vision.
Read More
Anypoint DataGraph
This year we’ve seen MuleSoft make some exciting additions to its offering. MuleSoft Composer and Anypoint DataGraph are two new products that promise to accelerate integration in new ways that go beyond the traditional programmatic consumption of REST APIs. “Rest” assured (pun intended!), REST APIs and API-led connectivity are still the foundation that every company needs to get right in order to efficiently drive reuse of assets and unlock their data. What’s interesting is that in most scenarios the consumers of said REST APIs are likely to require data to come from several ones at a time. Attached to this comes the need for significant additional effort, in the form of:
- obtaining access to each API
- writing custom code to fire requests to each API
- writing custom code to parse the responses from each API
- sieving through all of the API’s response fields – not just the ones that you need
So what can be done to reduce or avoid these efforts altogether?
Traditional REST may not be enough, but pairing it with a relational spec might be the answer. Allow me to take a step back and take you through a short overview of GraphQL.
GraphQL is a specification for a query language for your APIs. It was conceived in 2012 by Facebook and then popularised by big players like GitLab, Pinterest and Shopify, after its release to the public in 2015.
With GraphQL you define a graph schema that provides a complete and understandable relational description of the data entities in your APIs. Developers can then refer to this schema to write requests in the form of relational queries that allow them to obtain with a single request data that spans multiple related data entities, giving them only what fields they ask for and nothing more.
The best part is that all of this is achieved without requiring the consumers to develop any custom code! All they need to do is write the query.
Ok, so now you may have already worked out for yourself why GraphQL is important when talking about Anypoint DataGraph. Allow me, however, to spell it out anyways: Anypoint DataGraph implements the GraphQL specification. As such it enables enterprise architects to devise a unified schema of related data types using existing REST APIs, so that then this schema can be exposed as a service and queried using GraphQL.
The buzzword to focus on here is “relational”. You will get value out of this product when you consume data that has relationships defined in terms of “foreign keys”. Effectively, you can think of the data resources in your REST APIs as tables in a relational database – however the big difference is that your query results will not have a tabular structure but a tree structure, similar to an XML document.
Say now you’ve identified a bunch of REST APIs that fit the part.
How do you go about including them in your Anypoint DataGraph unified schema?
Each API you want to include must have its spec published on Anypoint Exchange and it must have an active and running instance. The interesting bit is that you can bring into your unified schema any API, even if not native to the Anypoint platform, so long as you have a working instance of it listening on an accessible URL – anywhere! Once an API is imported, the Anypoint DataGraph tool automatically picks up data types and their fields. These can be renamed as well as completely left out if necessary and relationships can be defined between the data types.
Anypoint DataGraph is a separately licenced add-on SaaS app. Beyond the obvious “having to pay for it”, this also implies that:
+ you don’t need to worry about its provisioning or maintenance. Behind the scenes it utilises an amount of vCores you want to allocate to it (yes! It eats up your vCore allowance!)
– it is not available for on-prem (however the APIs imported in the unified schema can live anywhere, so long as their spec is on Exchange)
The product also comes with a Query Builder web UI that allows you to write, test and profile GraphQL queries right away. With it you can drill down the queries’ making parts and see the time it takes to execute each.
“But how does all of this fit in with the API-led Connectivity model?” I hear you ask.
In a very simplistic way one can argue that this new service wraps both Process and Experience layers’ responsibilities in one neat package: on one hand it orchestrates for you REST API requests to fetch all your records across multiple data entities; on the other hand it gives you a tailored experience by presenting to you only the fields you are interested in – nothing more, nothing less.
So does this mean that if you get Anypoint DataGraph then you don’t need Process / Experience APIs anymore?
Well, not quite. You will still need your Experience APIs to present results in a different media type if your consumers can’t work with GraphQL. And indeed you will still need Process APIs to implement complex transformations beyond simple joiners on keys, and that can only be achieved via tools like DataWeave.
Anypoint DataGraph is not the first flavour of server-side GraphQL support that MuleSoft introduced.
Prior to this, MuleSoft had published an open source module that allowed you to program the GraphQL query resolvers as flows in your custom Mule apps, which meant a lot of coding was required to build out the GraphQL server service. Anypoint DataGraph by comparison does not require developers to write a single line of code to expose the service. It can all be achieved by clicks and no code. This alone is already a massive improvement from the previous product, but one must not forget that this is a product that is still in its infancy.
In fact, when wondering what the present and future of this product holds, a bunch of things come to mind.
Firstly the GraphQL specification includes “mutations”, a mechanism to allow manipulation of server-side data in write mode. For now Anypoint DataGraph only works in read mode and mutations are not supported.
Another sticking point is the lack of an ability to include in your client-side queries any filters defined as complex boolean conditions (e.g. filter out orders with a total that is greater than $100). For now all you can do is filter by exact match on fields marked as identifiers (e.g. CustomerId = 123) although to be fair a standardised way to implement filtering based on parameters is missing from the GraphQL specification itself.
In terms of protecting your service from abuse, for now non-configurable hard limits restrict things like the number of concurrent calls, timeout periods, number of fields per query and query depth (which loosely speaking translates to how many levels you can nest your query to ask for related entities). These hard limits can feel quite inflexible compared to the way MuleSoft users are used to define custom policies to protect the APIs managed through Anypoint.
What would be really interesting to see is whether Salesforce plans on bringing together the Anypoint DataGraph and MuleSoft Composer for Salesforce products by releasing a GraphQL connector for Composer thus enabling automated consumption of any data entity published onto the Anypoint DataGraph schema.
A Parting Thought
As a final parting thought it is worth reminding you that by nature the GraphQL specification gives developers the ability to fetch, through a single endpoint, data that resides on disparate systems of record.
Because of this there is a danger that a GraphQL endpoint may enable data access in a way that was not originally intended. The GraphQL specification itself recommends that Authorisation should be handled by the business logic layer, instead of the GraphQL layer, where it can become cumbersome, hard to maintain and inconsistent with the authorisation rules set out by the business logic layer. This means that when putting together your unified schema you really need to ensure that authorisation of your clients against the DataGraph service works in tandem with that of the DataGraph against the REST APIs in your unified schema.
Summary
In summary, this new product introduced by MuleSoft is a powerful SaaS tool for architects, which allows them to expose a GraphQL service by means of clicks and no code. This service materialises a new way to consume APIs, accelerating developers’ access to data that sits across disparate REST sources. Whilst this means that this product cannot bring immediate value to companies without a well-established application network, it promises to accelerate even further consumption for those with a good foundation of RESTful APIs.
Read More
Measure Success of your Salesforce Enhancements
Setting Objectives
Firstly, what is an “objective”? An objective is a thing aimed at or worked towards; a goal! There are many methodologies and plenty of jargon that surrounds objectives, but at its core, it’s a goal with a measurable outcome.
So how do we set these objectives? A simple way of approaching objective setting is applying S.M.A.R.T right at the beginning of the discovery phase for the project you are working on.
S.M.A.R.T – Specific, Measurable, Attainable, Relevant, Timely
To elaborate on this, you need to be specific in the who, what, when, where, and why. This is to remove ambiguity so that the objective cannot be open to more than one interpretation.
You also want to ensure that the objective is measurable. Are you able to measure the success of what you have implemented, have you taken the baseline of what you are measuring against? For example, let’s say the objective is to increase the efficiency of a quoting process in Salesforce. A way to measure this would be the time taken for sales users in the quoting stage of an opportunity, but how long does it take for sales users to quote using the system right now?
The objective itself needs to be attainable. An unreasonable objective will set you up for failure, so ensuring that the objective is attainable is a key to ensuring the success of your implementation. Then ask yourself, is the objective relevant? Is it a worthwhile investment of time, and will it meet the needs of the business? Lastly, how timely is it? Can we establish the urgency of the need to make these changes, and are we able to complete and achieve this objective in a manageable time period?
Objective categorisation
All objectives are different and will affect different parts of the business, a good way to make things easier for yourself when categorising these objectives is by splitting them into the following pillars:
- Financial – Is the objective going to have a positive impact financially?
- People – Is the objective going to have a positive impact on the employees that work within the business and make their lives easier?
- Customer – Is the objective going to enhance the customer experience within your business?
- Process – Is the objective going to improve the process within your organisation?
The majority of objectives will fit into these categories. Separating your objectives out into these pillars will make it easier for you to be able to set ways of measuring the outcomes of them.
How do we measure these objectives?
So we have set our objectives with our stakeholders and we have agreed they are measurable, but now we need to ensure we can report on these objectives.
Let’s take the example we mentioned previously:
“We want to improve the efficiency of our quote process”
For this example, the business is going to be implementing CPQ with Docusign, so let’s lay out which areas of the business this will impact along with how it will impact them.
Reduce the time taken to quote, therefore, we are able to send out more quotes in a timely manner. This will require less time to create and send quotes to customers and we would expect to see more business coming through due to quicker response times.
Measure: Increase in sales
Enable users to spend less time configuring and writing up quotes, thereby making their lives easier.
Measure: User feedback
Reduce the time taken for the customer to receive quotes, thereby benefiting their experience with the business and increasing the likelihood of them not going with competitors.
Measure: Customer feedback on the sales process
By creating a slicker, smoother process to quote out of the system, the speed of quoting is significantly improved.
Measure: Time taken in the quoting stage of an opportunity
Get creative when defining how you are going to measure your objectives. For example, we are reducing the time taken to send quotes out of the system. So in this instance, we could try and gain insight into what the average salary/cost of a salesperson is and compare the time taken in the cost of creating a quote in the system currently. You can then apply a monetary value to the time spent creating quotes.
In conclusion, setting objectives and measuring against the baseline that you have taken will demonstrate value and show how impactful the smallest of changes can be for your business.
Read More
Slack-First Customer 360
What is so good about it?
The working world has changed as we know it. Most organisations now offer remote working roles and have seen their workspace move to a ‘work anywhere’ environment. In response to this shift, Salesforce has introduced Slack-First Customer 360, a virtual HQ allowing everyone in sales, service, marketing and analytics to communicate and collaborate across systems – with Salesforce being the central hub.
With Slack-First Customer 360, sales, service, marketing and analytics are powered and automated in channels within Slack to connect teams and streamline workflows built around data. And with Slack Connect, companies can work securely with external partners/customers to drive stronger relationships and see faster results.
Slack-First Sales

With sales reps using Slack, sales cycles are accelerated by an average of 15%. In this new landscape, Slack gives your sales team the ability to work even more effectively. When everyone collaborates in Slack/Connect, they’re able to:
- Receive lead notifications
- Log calls and meetings
- Create opportunities
- Review and submit updates to records
- Listen to sales calls
- Reduce routine tasks
- Move deals through the pipeline quickly
- And more…
With all of this done in real-time, Slack drives growth from anywhere. Granting everyone visibility of the pipeline, teammates can share insights and updates in public channels to increase transparency and engagement.

Sales best practices can be captured, documented and searchable without the need to remain in channels. Sales reps can react quickly and stay engaged with automated workflows that can keep work life interesting (e.g gamifying converted leads, customer signatures and won opps through a leaderboard). Through this you can celebrate your team’s wins!
Slack-First Service

In a new world of tech, customer expectations are higher than ever before and building customer loyalty is crucial for long term success. With Slack-First Service, service agents get instant access to relevant case data, improving collaboration in dedicated channels that has resulted in an 11% improvement in customer satisfaction scores. When everyone collaborates in Slack/Connect, they are able to:
- Receive notifications on high severity cases
- Create dedicated channels around products, themes and topics
- Review and submit updates to records
- Get nudges on cases
- Search answers and knowledge shares historically through Slack
- And more…
These innovations have aided service professionals to adapt in finding solutions quickly and solving problems for customers.
Slack-First Marketing

Slack helps remove friction from your processes by connecting the marketing team to other key players in a shared digital workspace. From intelligent AI-driven insights and automated workflow notifications, Slack ensures teams can take action fast so that campaigns can stay on track as well as collaborate and approve changes instantly.
In a world where engaging customers in real-time is a top challenge, 76% of marketers agree that Slack has improved their ability to make quick decisions.
When everyone collaborates in Slack/Connect they are able to:
- Automate alerts and grant approvals
- Start huddles to discuss issues
- Integrate Slack with social media apps to receive updates directly in Slack
- Monitor performance
- Streamline social listening and responding to customer feedback
Slack-First Analytics
Within a Tableau-integrated Salesforce organisation, Slack and Tableau expand the visibility of analytics across the organisation and enable customers to stay on top of data from anywhere.

View Slack analytics data directly in Salesforce via predetermined dashboard and reports. Measure success and make smarter decisions fast from automated notifications and watchlist digests to provide daily updates on selected metrics and trends.

Considerations When Rolling Out Slack
In order to be successful when making big changes, you have to plan ahead, continually gather data and make genuine improvements to get the most out of Slack.
There are four considerations when rolling out Slack:

Naming Conventions
Add hashtags and correctly named channels will allow Slack to naturally group channel ordering within the UI.
Workflow
Automate routine tasks and consider high manual processes that cost valuable time. Use Salesforce integration to get notifications in Slack. Increase transparency and productivity.
Integration
Slack workflows and integrated tools can help automate reminders and approvals.
Behaviour
Establish guidelines for using Slack, such as reacting to messages with emojis, pinning important docs/resources to channels so newcomers find it quickly, searching for info first before posting in channels in case the information is already available in Slack.
The Power of Automation
With Salesforce and Slack integration there are many ways in which automation can power your business.
From lead notifications and approvals in Slack-First Sales, case history and knowledge shares with Slack-First Service, streamline social listening with Slack-First Marketing and watchlist digest form Slack-First Analytics, automating processes is a driving force within the integration.
Some of these processes include:
- Configure message destinations in Slack Setup to be used with the “Send to Slack” invoiceable method in Process Builder

- Send messages and content directly to Salesforce records with the Salesforce connected app in Slack.
- Integrate Slack channel messages directly on Lightning pages/components so that you can see conversation history in real time.

- Manage standard and custom “Slack Alerts” in Slack Setup to notify channels on record updates such as successful opportunities and leads with hot ratings.
- Create workflows directly in Slack with Workflow Builder to automate tasks and processes.

- Build apps in Slack that help increase team engagement and productivity. Get your apps to automatically reply as well as create tasks and aid your team in Slack via events and web API’s that can be configured in hosting providers such as Heroku, Amazon Web Services, Google Cloud and more. Use Glitch or Ngrok to develop and test live projects using AI.

- Use Slack’s UI framework to power your app and produce interactive content such as buttons, multi-select menus, time pickers and overflow menus to collect info and trigger a link of a complex workflow. For example, approval processes or channel polls. Build all of this seamlessly with Slack Block Kit Builder.

What’s next?
The Salesforce and Slack integration has proven to be a handy tool to combine and optimise businesses moving forward. We have seen improved collaboration, searchable conversations, and greater transparency as a result.
Not only this, but the power of automation between the two systems, both with clicks and code, make this a good fit for admins and developers – not only just for businesses as a whole – but for Salesforce professionals to pick up a new skill and earn credentials on the platform (see Slack certifications here – https://www.slackcertified.com/). Slack-First Customer 360 is available with the new Winter 2021 Release and can be installed today free via the AppExchange.
Read More
Why MuleSoft Sucks (except it doesn’t)
It seems that MuleSoft’s major marmite effect boils down to three major criticisms:
Lack of ROI
Companies have been ripping out MuleSoft because they aren’t realising the promise of huge return on investment.
Why enterprise software?
Anyone with half a brain can create their own bespoke solution that can serve specific business needs while being far more cost effective.
It’s overpriced
There are so many integration tools out there that can do what is required for a fraction of the licencing cost.
So if this is the case, why do people keep buying it? Is MuleSoft’s marketing just that effective? Let’s delve deeper into each of these three points and find out why.
Firstly, the lack of ROI
I’m not one to call someone’s baby ugly, but the reason many companies aren’t seeing ROI is simply due to poor implementation and adoption. Yes, I know that may seem like a cop out answer but it’s often very true. Using MuleSoft in the same way you would use a Boomi or Jitterbit is doomed to failure. There needs to be change in not just the technology, but the people and process as well.
The biggest factor that contributes to realising true value with MuleSoft is reuse. Should best practice be properly followed, each successive project undertaken becomes cheaper and faster to complete. This exponential growth of reusable APIs is akin to the accumulation of an amazing herb and spice rack.
You have to invest in certain ingredients for each recipe, but as time goes on you can reuse the ingredients from previous recipes, making future ones cheaper and easier to make (Christ, that was a stretch).
Adopting a C4E is also critical to success. Many organisations skip this step and simply assume that everyone in their organisation will develop new APIs and integrations following best practice with a three-tiered architectural approach.
This often isn’t the case. Without the correct governance and people management, MuleSoft will incorrectly be used like any other integration platform and the level of reuse, and therefore ROI will dramatically decrease. C4E adoption doesn’t have to be time consuming or expensive either, ThirdEye have developed their own Plug & Play C4E that can be implemented in just a couple of weeks for minimal cost.
Buying market leading software is no guarantee of success. There needs to be a conscious effort all around it to ensure that ROI is realised. Take a look at some of the most successful MuleSoft customers out there. Their success is due to key evangelists making sure that MuleSoft is done right.
‘I can do this cheaper and better myself’
Next, on to the ‘I can do this cheaper and better myself’ argument. I don’t want to doubt or underestimate you or your team’s talents. In fact, I’m confident you could build a cheaper solution using custom code and open source technology that serves the immediate needs of a business. For a lot of organizations, this is the more attractive option, especially those that sit within the mid-market space.
However, this is typically very short term thinking. These custom solutions may seem great at first, providing real value and quick ROI, but this is often short lived. The long term issues will almost inevitably begin to rear their ugly heads.
If you are to go down a point-to-point integration path, it almost certainly won’t leverage reuse. It will quickly start to become a mess resembling a can of cheap tinned spaghetti that’s been knocked to the kitchen floor. You’ve all seen those PTSD-inducing diagrams that look about as easy to untangle as a pair of wired headphones that have been in your pocket all day.
This brittleness can have severe impacts on your business, seriously hampering the speed and agility you need to compete in the modern business world. The inability to deploy new features and create new integrations without breaking something is the thorn in the proverbial backsides of countless organizations.
MuleSoft’s simple three-tiered approach alongside it’s composable and reusable APIs remove this pain by reducing technical debt and dramatically lowering cortisol levels worldwide.
The Anypoint Exchange also provides a wealth of custom connectors, accelerators and assets that massively reduce development time and time to market allowing companies to get new features out to their customers before their competitors do. These assets are also constantly being updated and improved, futureproofing your technology stack.
Cost
Finally, cost. MuleSoft may seem expensive at first. Especially when compared with other cheaper options on the market. It’s often compared with a Ferrari: it looks great, has high performance, but is totally unnecessary for driving round the city.
However, I would argue that the current market is not comparable to city driving, and is in fact more like the autobahn. Nimble competitors leveraging the best in breed technology are racing ahead, leaving the 2003 Nissan Micra slowing shrinking in the wing mirror. MuleSoft isn’t just a simple integration tool that connects systems in a point-to-point fashion. It’s a fully fledged API Led platform that can facilitate rapid growth. A Ferrari that will leave competitors in the dust.
The licencing models are also very flexible and easily scale at the pace in which an organization requires it to. There are a variety of options with different features depending on requirements and the number of vCores is dependent on the size of those requirements. Companies can also flexibly change this when needed.
Many people also don’t consider the additional benefits that are included with the licencing costs. Things such as a dedicated Customer Success Manager and access to MuleSoft’s Solution Architects are not standard practice with other integration platforms and are actually hugely useful to new and long-term customers. Also, the vast amount of documentation and training available online prevents people from repeatedly banging their heads against the wall when coming across a blocker.
All in all, MuleSoft is nowhere near as expensive as many are led to believe, and the pricing models can be far more cost effective than those that charge per API call. A model that can initially seem like great value, but adds up massively with scale.
So there it is. My attempt at unpicking some of the major criticisms of MuleSoft. It’s by no means a perfect product and has its own drawbacks. However, it is still the best integration platform on the market and can transform a business with new routes to market, faster development of new features, access to a potential goldmine of data, and dramatically lowered development costs.
If you’re struggling to realise ROI with MuleSoft or aren’t sure if it’s the right product, you know who to call.
Read More
Keep your customers happy these holidays with Marketing Cloud
Painless
With so many options to purchase from, customers are increasingly turning to companies that offer quick, painless shopping experiences. People want a smooth buying journey, from adding products to their basket, completing the transaction, through to purchase confirmations, any friction point can lose a company a conversion. Real-time engagement with customers is, therefore, key for creating contextually relevant experiences. Something Interaction studio specialises in!
Using Einstein to harness the power of AI, you can recommend products and/or content to specific customers based on their online shopping characteristics, providing real-time suggestions on where to go next in their buying journey. Combining both offline and online behaviours with algorithms in Marketing Cloud to match customers to profiles allows relevant content to be presented during the buying process.
Customers are also more likely to be repeat customers where the initial buying journey was found to be smooth and painless, so it is more important than ever to ensure you are listening to what makes your customers’ experience easy. Progressive profiling used to prefill forms and A/B testing on website pages are simple low-effort tactics you can implement within your customers’ buying journey to help make their browsing more enjoyable.
Personalisation
Customers’ window shopping on your website can provide invaluable information to help drive conversions. Leverage: click behaviours, page views, and attributes gathered during form completions to segment your customer base into specific audiences and drive content or product recommendations.
Queries, filters and code can all be used to further filter customers into Data Extensions based on attributes. This granular data can provide suggestions for customers’ next move on the website and ensure every possible customer journey is accounted for.
Social media is also a large part of customer’s shopping experiences, with suggested ads and banners being displayed on every web page they visit. It is therefore imperative that you are displaying the correct adverts to the correct audience at the correct time! Advertising studio allows you to do just that.
Using similar audiences to reach out to new customers on Facebook and Google while not advertising to existing customers, Advertising studio allows you to optimise your marketing budget and save that extra cash for the holiday party. What could be better?!
Preferences
Knowing which channel to market to your customers is essential, with SMS, Email, and Push Notifications all a possibility. Use a custom-built preference centre to capture your customer’s preferred method of communication and ensure your messages are delivered via the right channel with no annoying cross-channel messaging.
With screen time increasing due to shorter commutes and greater flexibility in WFH environments, push notifications straight to customers’ handsets have seen a surge in popularity. The majority of customers, however, tend to be logged into multiple applications at the same time and find a constant barrage of texts, emails, and push notifications overwhelming.
Using Journey Builder, you can create tailored journeys to send messages via apps in a controlled manner, creating push notifications when your customer is on your app and SMS and email at intervals during a time frame you specify. Ensuring you do not spam your customers with messages on every platform is a great way to avoid customers unsubscribing.
Understanding your customers needs and meeting expectations is the most pivotal part of creating an awesome marketing strategy. Customers remember the good experiences they have and encourage friends and family to follow in their footsteps and purchase from the same business. Using the tips above, Marketing Cloud can be used to keep your customers happy over the holidays which in turn I’m sure will keep you happy too!
Read More

