Thankfully for Project Vita, most office plants don’t require second-by-second readings that could cause a catastrophe if not known about and acted upon in time.
However, like all well-designed architecture, we aimed to make it as scalable as possible in order to harness its power and apply it to many different industries. Whether it be Construction, Manufacturing, Medicine, Education, we have been able to find use cases that can bring about benefits and provide insight from the application of this technology.
Due to the nature of Salesforce potentially needing to receive and process a high volume of requests per minute, we chose to use the power of Platform Events and the Salesforce Event Bus .
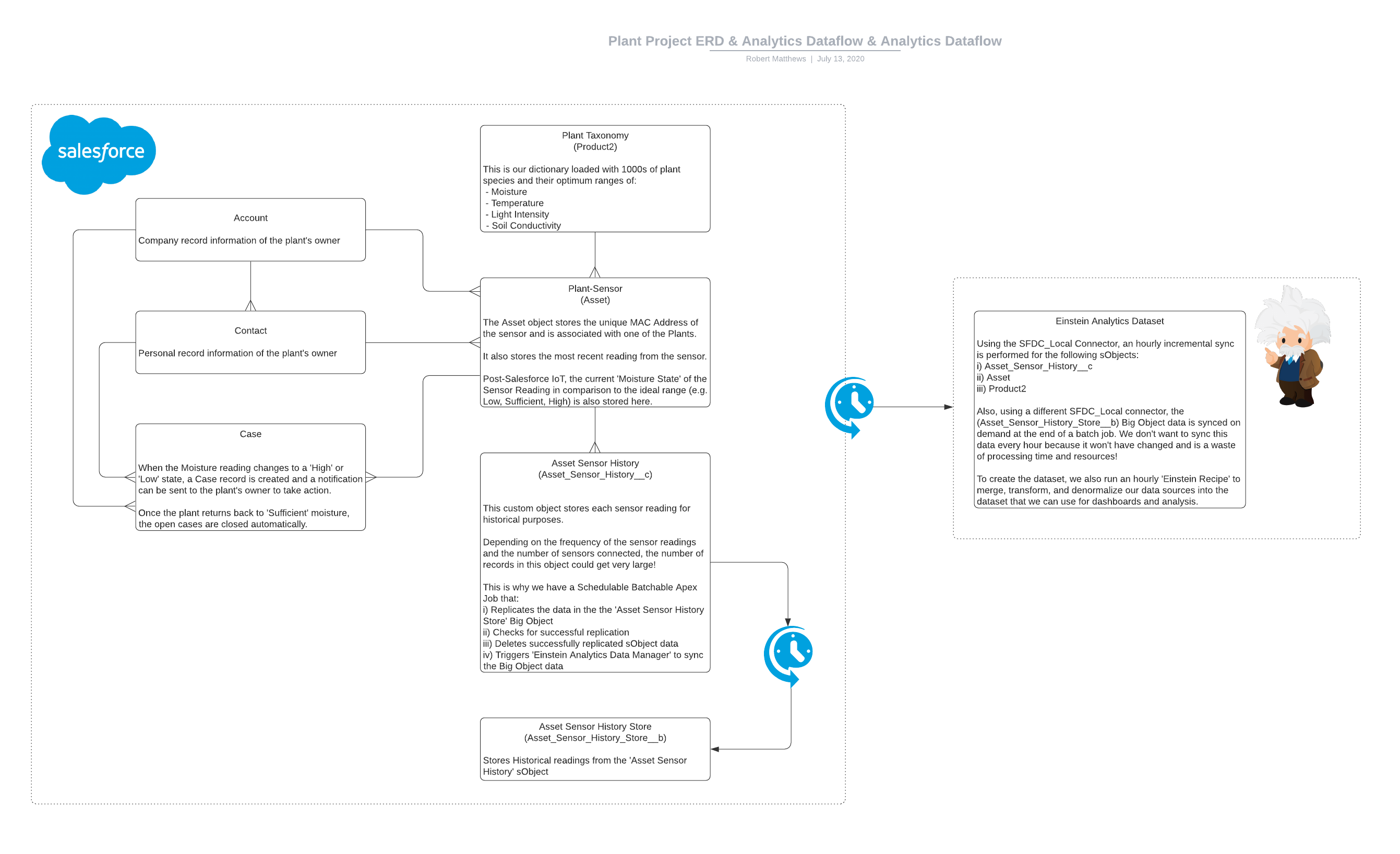
The setup of a platform event on Salesforce is very similar to that of a custom object where we created the event and it’s custom fields all through the UI. For any automation and processing we needed to be able to uniquely identify the sensor the platform event was created from with a record for an sObject in Salesforce. For this we used the ‘MAC Address’ of the sensor (for the full high-level ERD, see below).
The next step was to choose how to process the Platform Events.
Processing Platform Events
ThirdEye prides itself on being at the cutting edge of Salesforce’s new features and platform capabilities, and as such, has amended the processing of the platform events as recommended changes to the platform occurred:
1. Salesforce IoT (Retiring October 2020)
- ‘IoT MiFlora Context’ linked the Platform Event to the Asset object using the unique ‘MAC Address’ identifier
- ‘IoT Moisture Orchestration’ was created against the Context and served to set and retain the state of the asset’s moisture as each of the platform events were received. It also processed logic against the message and when the Moisture State changed, a case was automatically created.

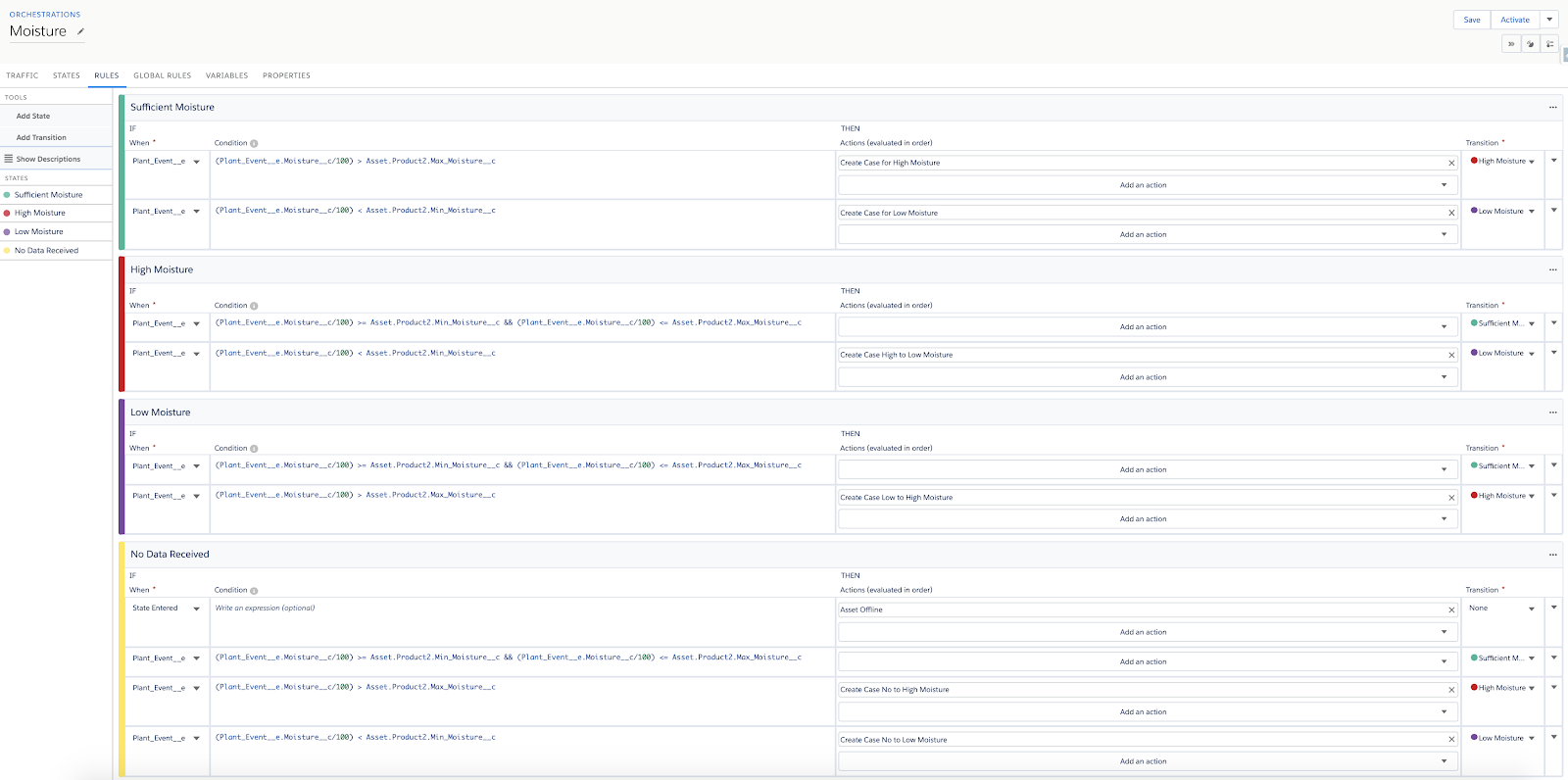
2. Process Builder + Flow Builder
Foreseeing the retirement of ‘Salesforce IoT’, we migrated the logic to Process Builder and Flow. The only structural addition we needed to make was to add and maintain the ‘Current Moisture State’ on the Asset Object:
- Process Builder listens for Plant_Event__e Platform Events, gathers related object information about the specific Plant, and passes this information to Flow for assessing the Moisture State.
- The Flow determines if the state has changed since the last event and creates a case if it has changed to ‘High’ or ‘Low’ Moisture. We also notify the plant’s owner to advise them of what action to take.
- Once the Moisture State has changed back to ‘Sufficient’, the Cases for the Asset are automatically closed.


We also have a scheduled Flow that determines if the last sensor reading was over a certain amount of time ago. If it is, the Asset is marked as ‘Offline’ and the plant’s owner is notified.
3. Flow Builder (Summer ‘20 Release)
Instead of using Process Builder as the listener for the platform event, the ‘Salesforce Summer ‘20’ release allows you to do all of this from one automation tool, Flow Builder!
Einstein Analytics & Historic Sensor Readings
It was all well and good getting the notifications that our plants were thirsty but we also wanted to be able to visualize the data and see it for ourselves.
So, for each of the processing automation above we also stored the readings as a record in a custom sObject object called ‘Asset Sensor History’.
After setting up an hourly incremental sync for the sObjects and Dataflow in ‘Einstein Analytics Data Manager’ for this historical data, we could use the resulting dataset to show on a Timeline chart. However, the question of scalability loomed over us again when calculating the timely depletion of sObject storage.
It was time for us to use a Big Object.
To make it configurable from the Setup UI, we created a Schedulable Batchable Apex Job that:
- Replicates the data in the the ‘Asset Sensor History Store’ Big Object from the subject
- Checks for successful replication
- Deletes successfully replicated sObject data
- Triggers ‘Einstein Analytics Data Manager’ to sync the SFDC_LOCAL Connector Big Object data
Now we had both of these in Analytics we created a scheduled ‘Recipe’ to merge, transform, and denormalize our data sources into the dataset that we now use for dashboards and analysis.
High-Level ERD & Analytics Dataflow
Project Vita’s chapters:
- Chapter 1 – Will Your Desk Plant Survive Covid-19?
- Chapter 2 – The Quest for Data
- Chapter 4 – Retrieving Data with a Scalable Sensor Solution